Generating embeddings
Embeddings generation works in the following way:- Every
sync-period(5 minutes by default) graphite queries your data and searches for new data (or existing data that changed recently). - It extracts the relevant data for generating the embeddings
- It requests OpenAI to generate embeddings
- It stores the embeddings alongside the data.
Querying embeddings
Once the embeddings have been generated you can leverage pgvector to perform any operation you may want. In addition, Auto-Embeddings will automatically provide two new queries;graphiteSearchXXX (search using natural language) and graphiteSimilarXXX (search for objects similar to a given object), where XXX is a name given by you.
Demo
To demonstrate how to configure Auto-Embeddings we will use an example project where we are storing movies. Before we start, let’s start by explaining the project. Our project contains a single table calledmovies with the following columns:
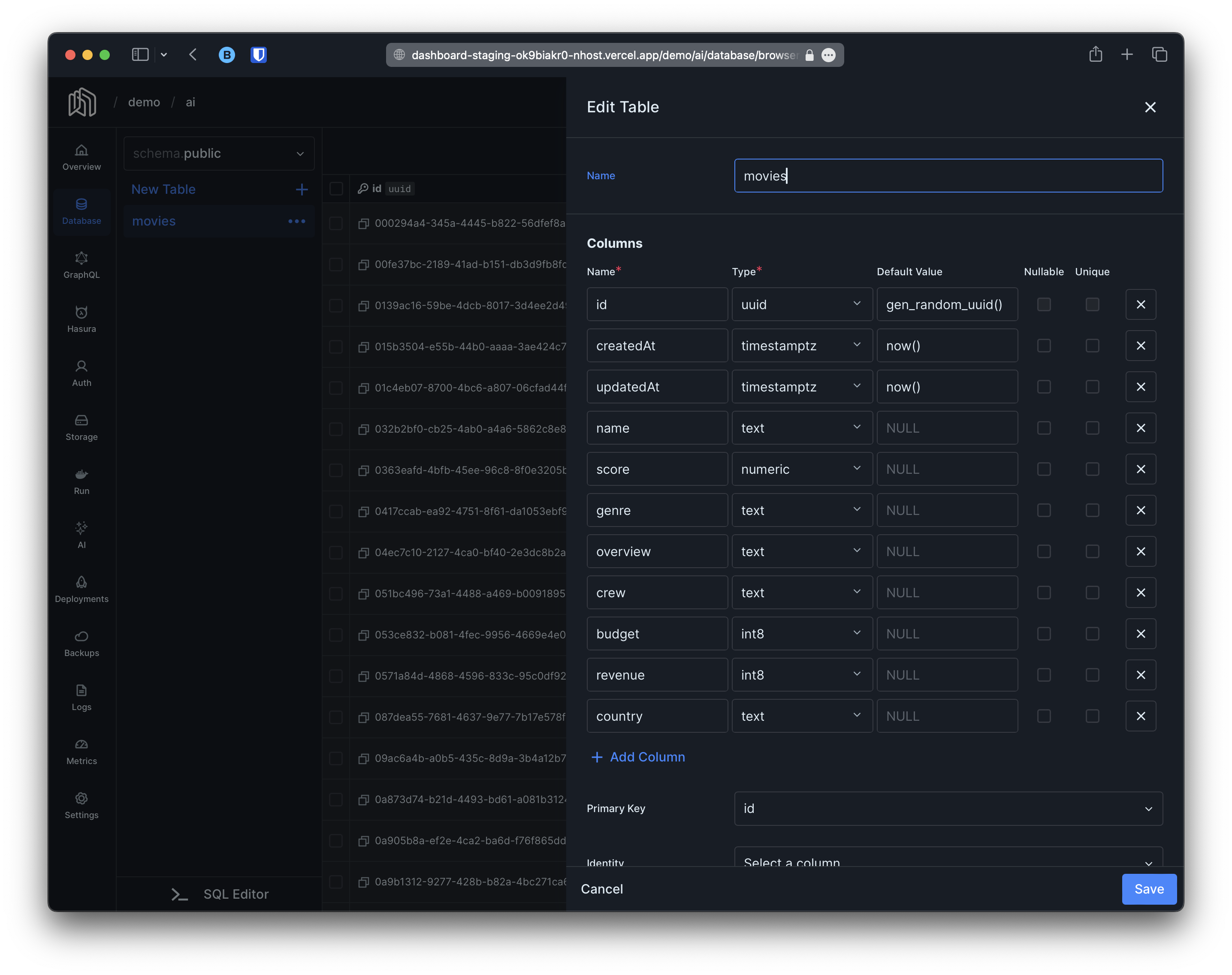
name, genre and overview.
Preparing your database
Before we can start generating embeddings we need to prepare our database:- First we are going to need a column to store the embeddings.
- Finally, we are going to need a mechanism to detect when embeddings need to be regenerated.
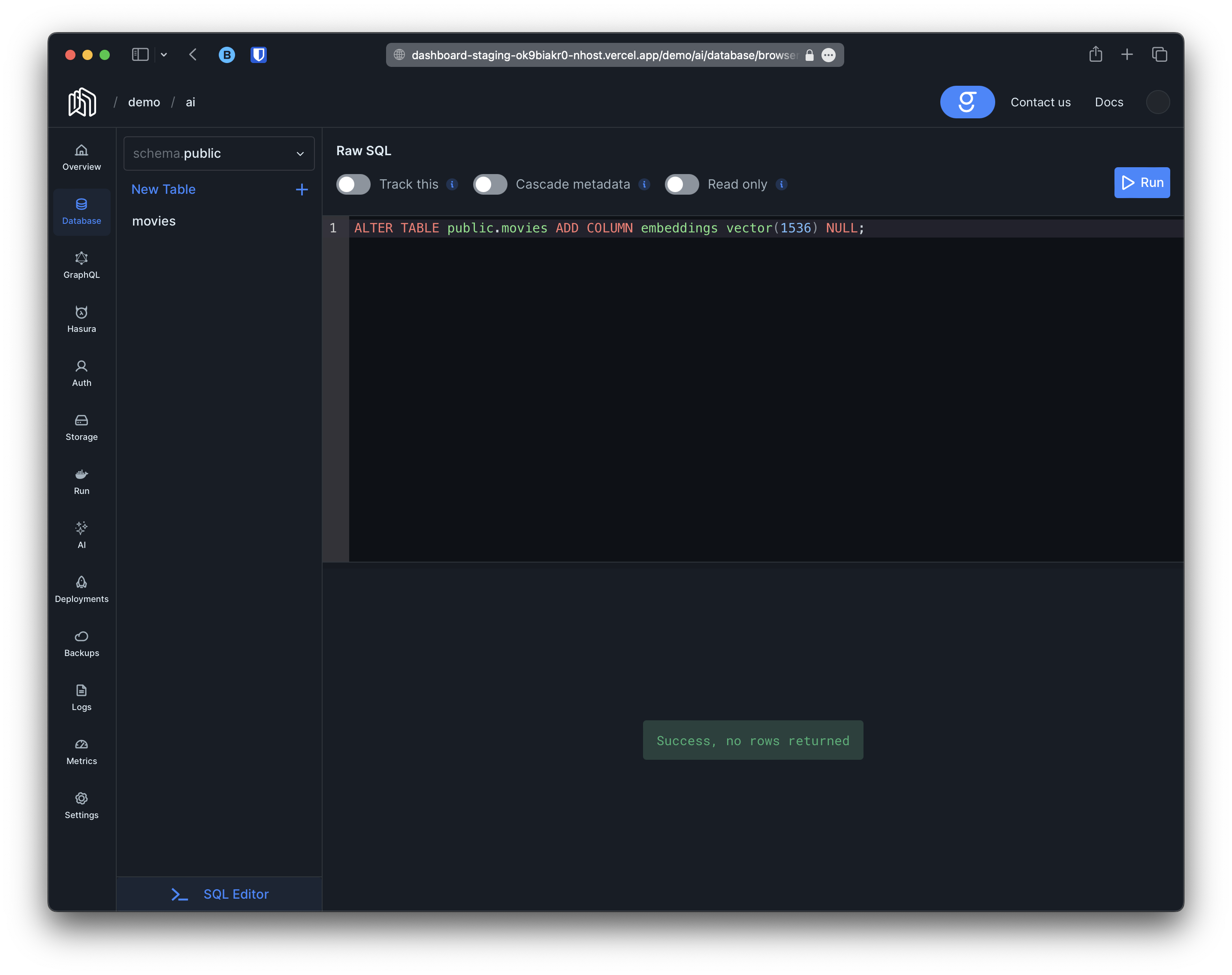
Embeddings Column
Creating a column to store embeddings is as easy as creating any other column. Just make sure it is of typevector(1536) and it can be NULL. For our project we can simply go to the SQL tab and create a migration with the following content:
Detecting Changes
On everysync-period graphite will perform a graphql query to get all the rows that have outdated embeddings. This means we can build this query in a way that:
- Gets the data we need for the embeddings.
- Retrieves objects with the embeddings column set to
NULL. - Leverages another mechanism to detect which rows needs their embeddings regenerated.
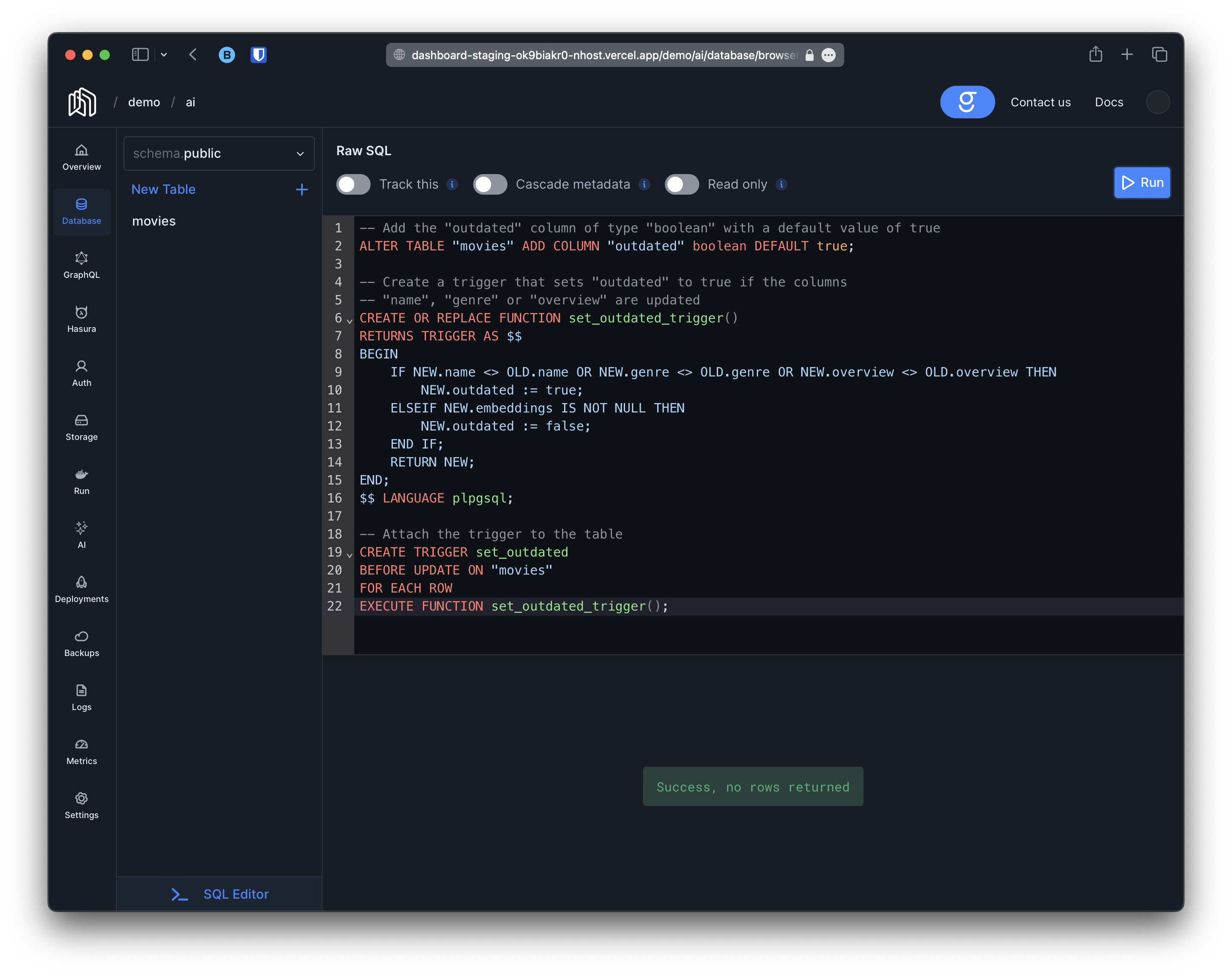
- Add a column
outdated(boolean) to indicated whether the row is outdated or not. - Add a postgres trigger and function that will set the
outdatedcolumn to true everytime there is a change to our data.
graphite’s query will be (more on this later):
This mechanism has the advantage that is simple enough and fully handled by postgres so you don’t need to worry about it. In addition, it should be flexible enough to cover most cases. For very complex use-cases you could skip the postgres function and trigger and update the
outdated directly from your application or you could use some completely different mechanism (i.e. a computed field). The important bit is that graphite needs to be able to make a graphql query and get the relevant rows and data.Configuring Auto-Embeddings
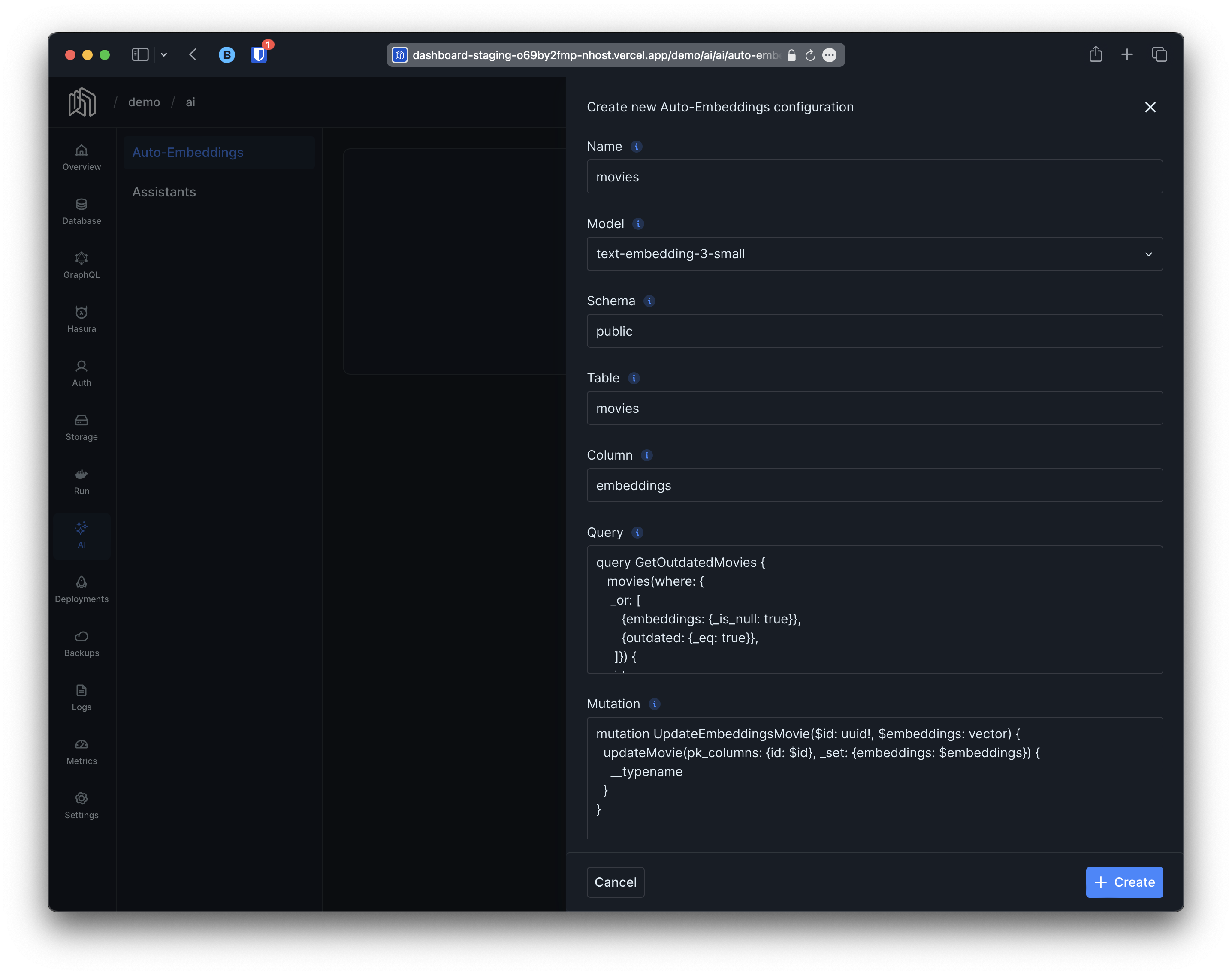
Now that we have prepared our database we can proceed to configure Auto-Embeddings. You will need the following data:- A unique name. We are going to use
moviesfor this particular example but it can be anything. This will determine the name of the GraphQL queriesgraphiteSearchXXXandgraphiteSimilarXXX. - The location of the embeddings column; schema, table and column names, in this example
public,moviesandembeddingsrespectively. - A GraphQL query to retrieve the outdated rows and their new data (the query we worked on in the previous section)
- A GraphQL mutation that takes the
idof the object, the embeddings and that updates the relevant object. For instance, in this particular example the following mutation would suffice:
- dashboard
- graphql
Aftermath
Embeddings Generation
After executing the mutation above two things will happen; the first one is that if we look at our logs we will start seeing entries like this on the nextsync-period:
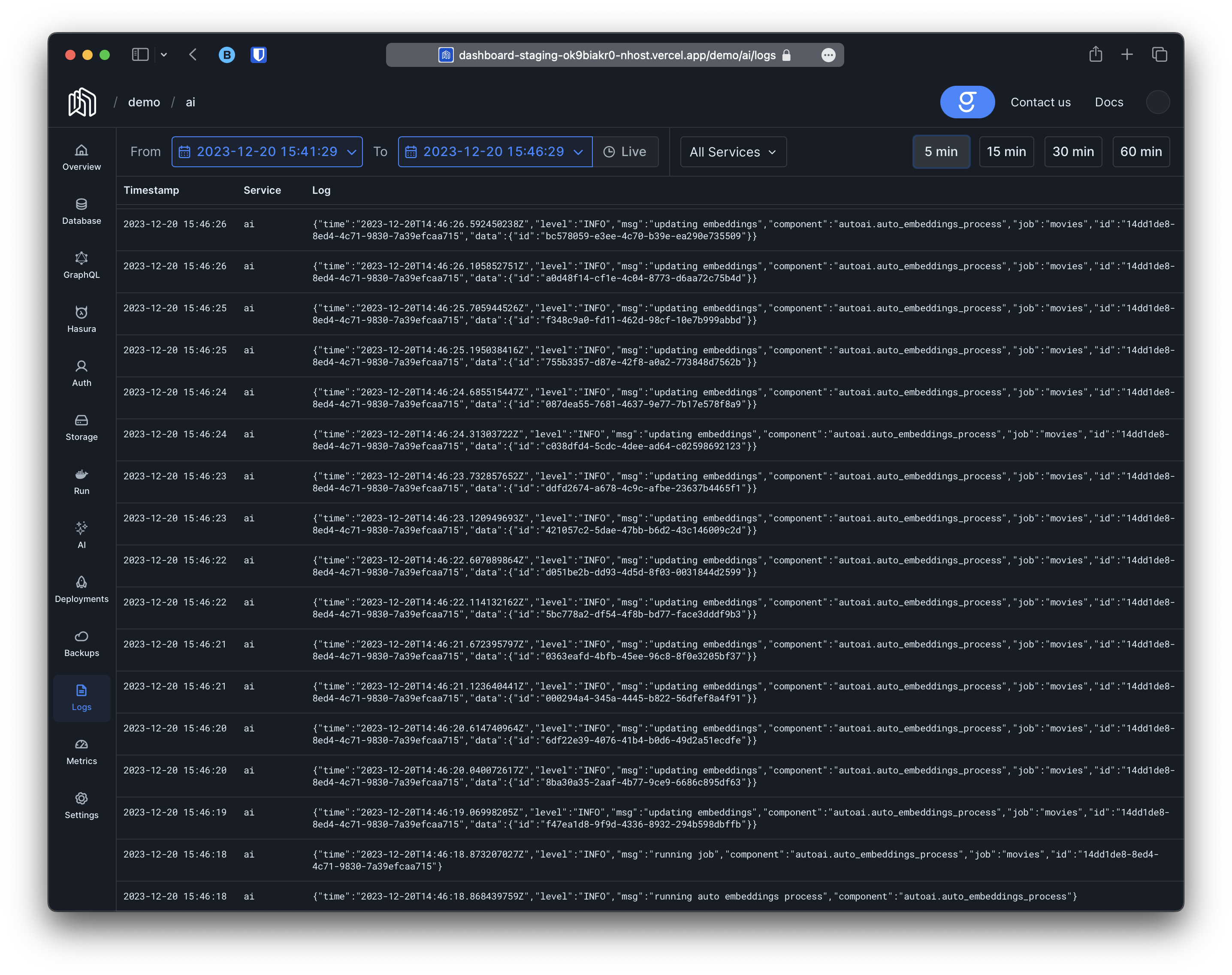
embeddings column set to NULL:
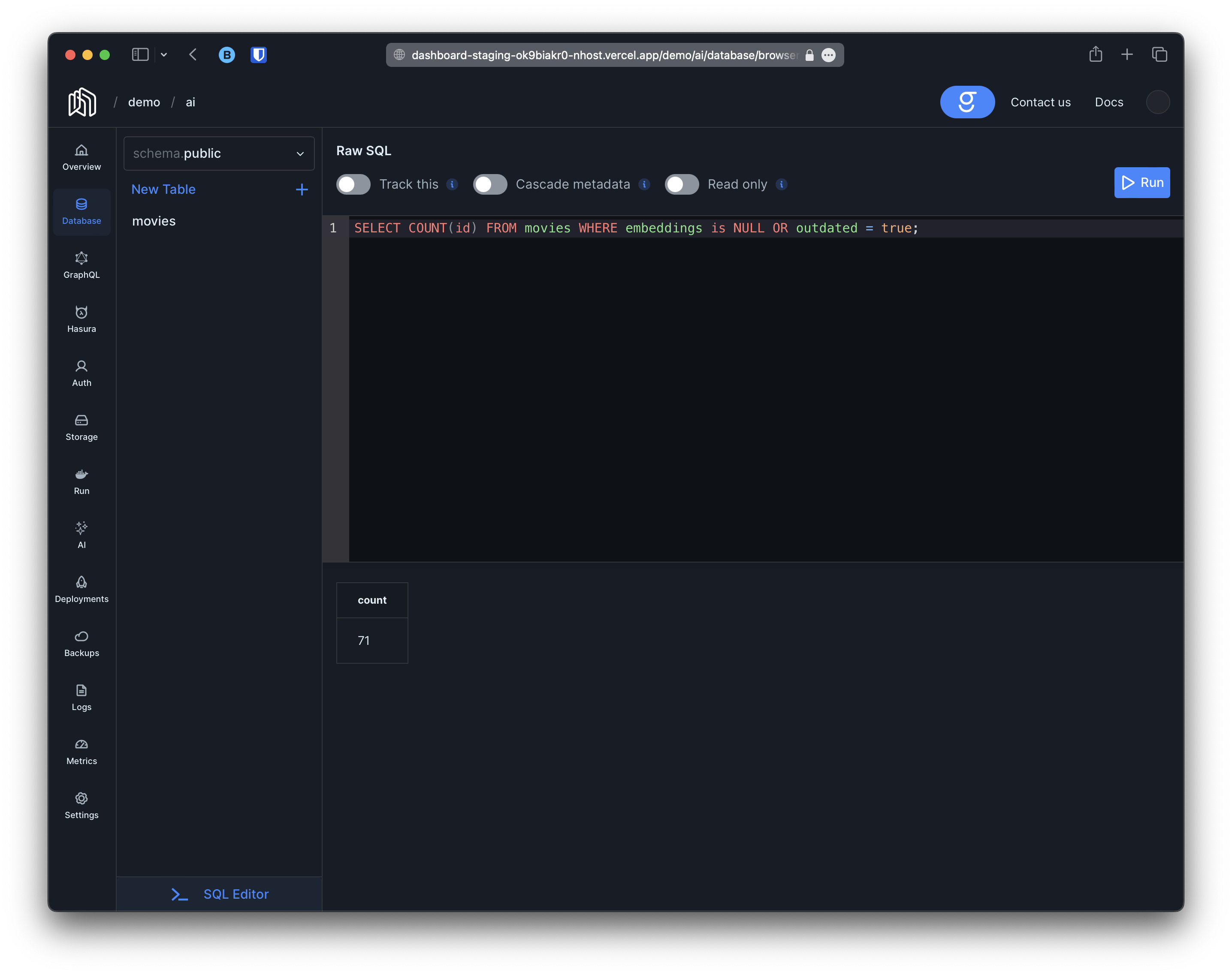
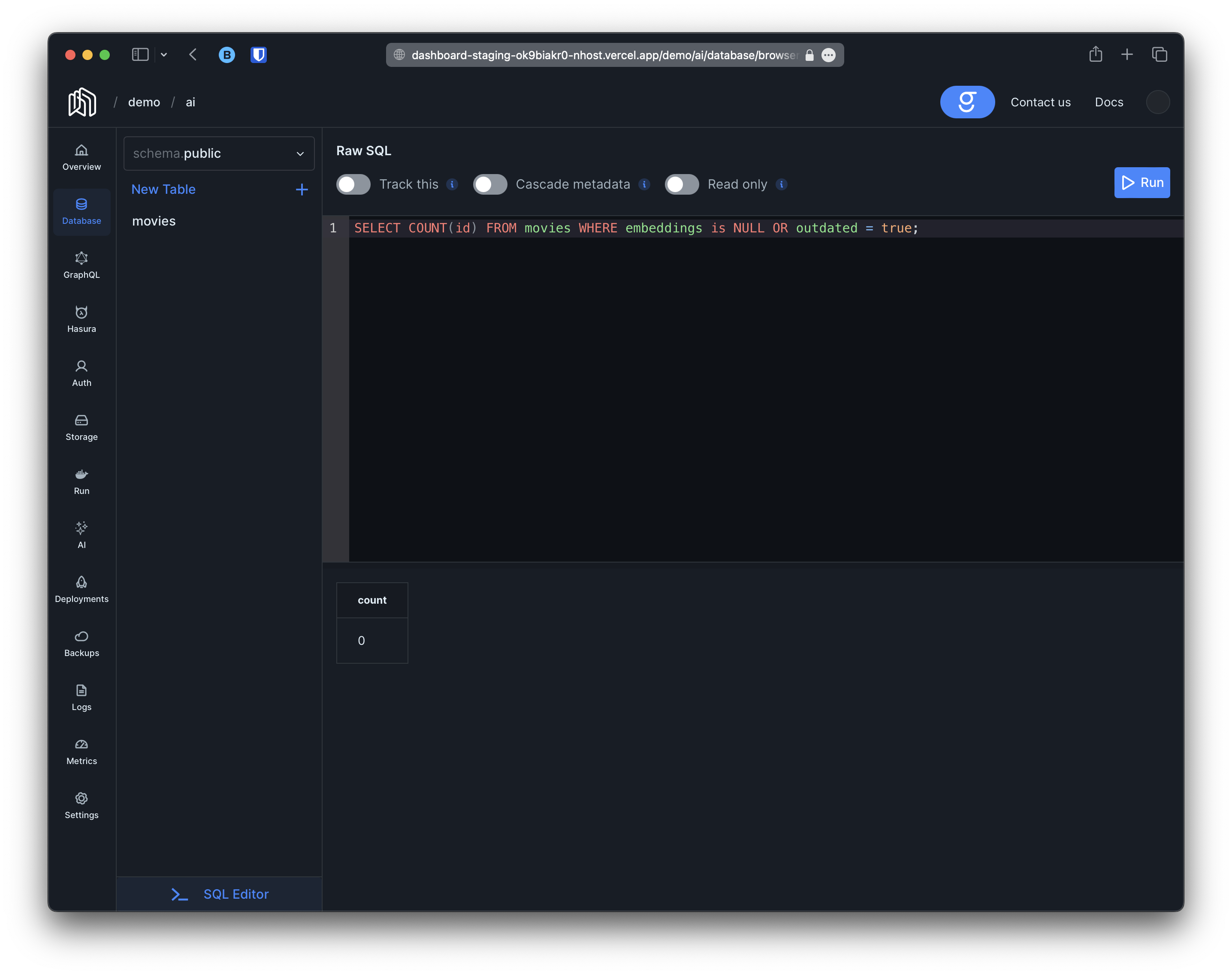
Natural Language and Similarity Search
The second thing that will happen is that the queriesgraphiteSearchMovies, graphiteSearchMoviesAggregate, graphiteSimilarMovies and graphiteSimilarMoviesAggregate will be created. These queries will work similar to the standard movies and moviesAggregate queries provided by hasura and will respect the same permissions but they will also allow you to query movies using natural language or other movies for comparison. For instance:
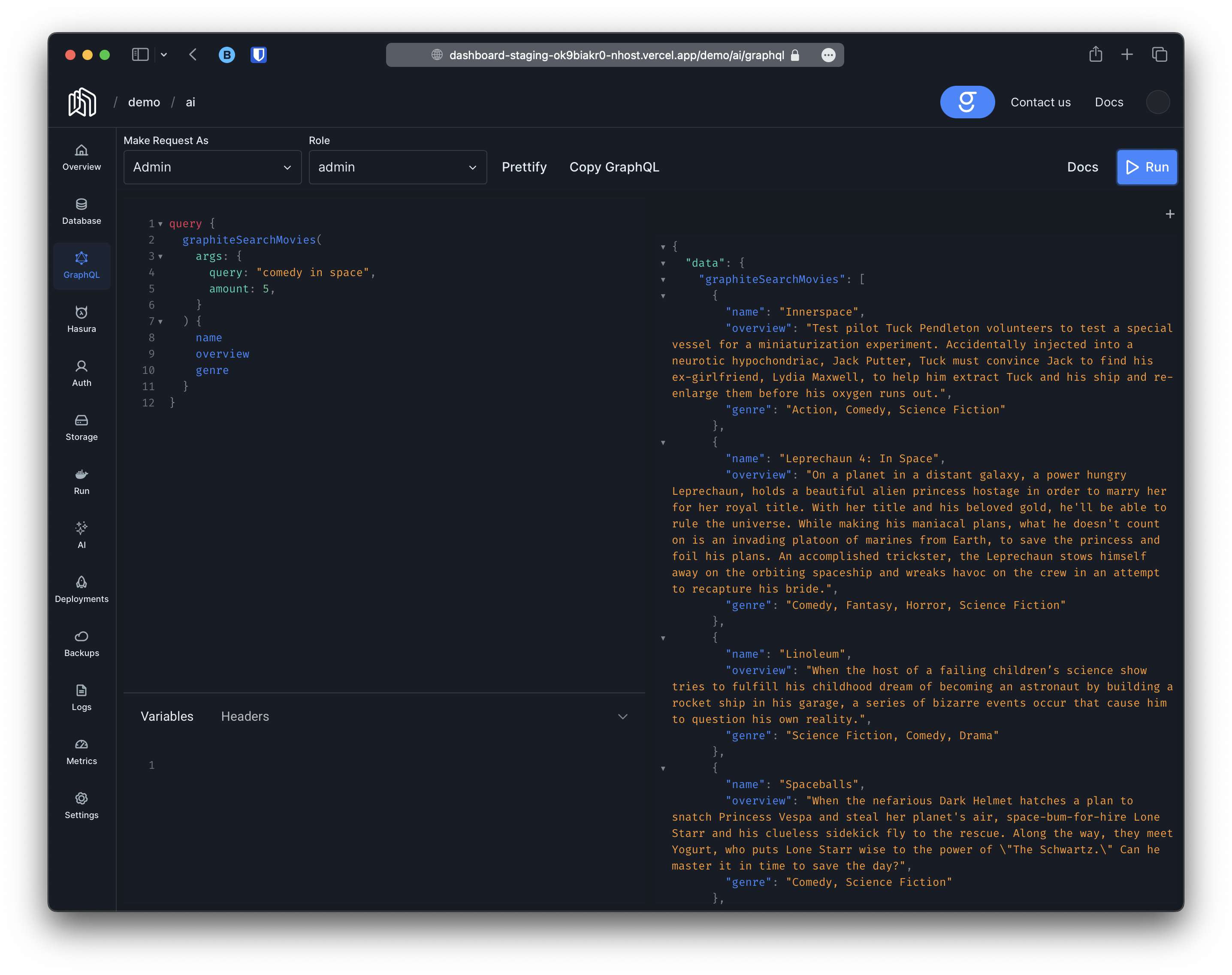
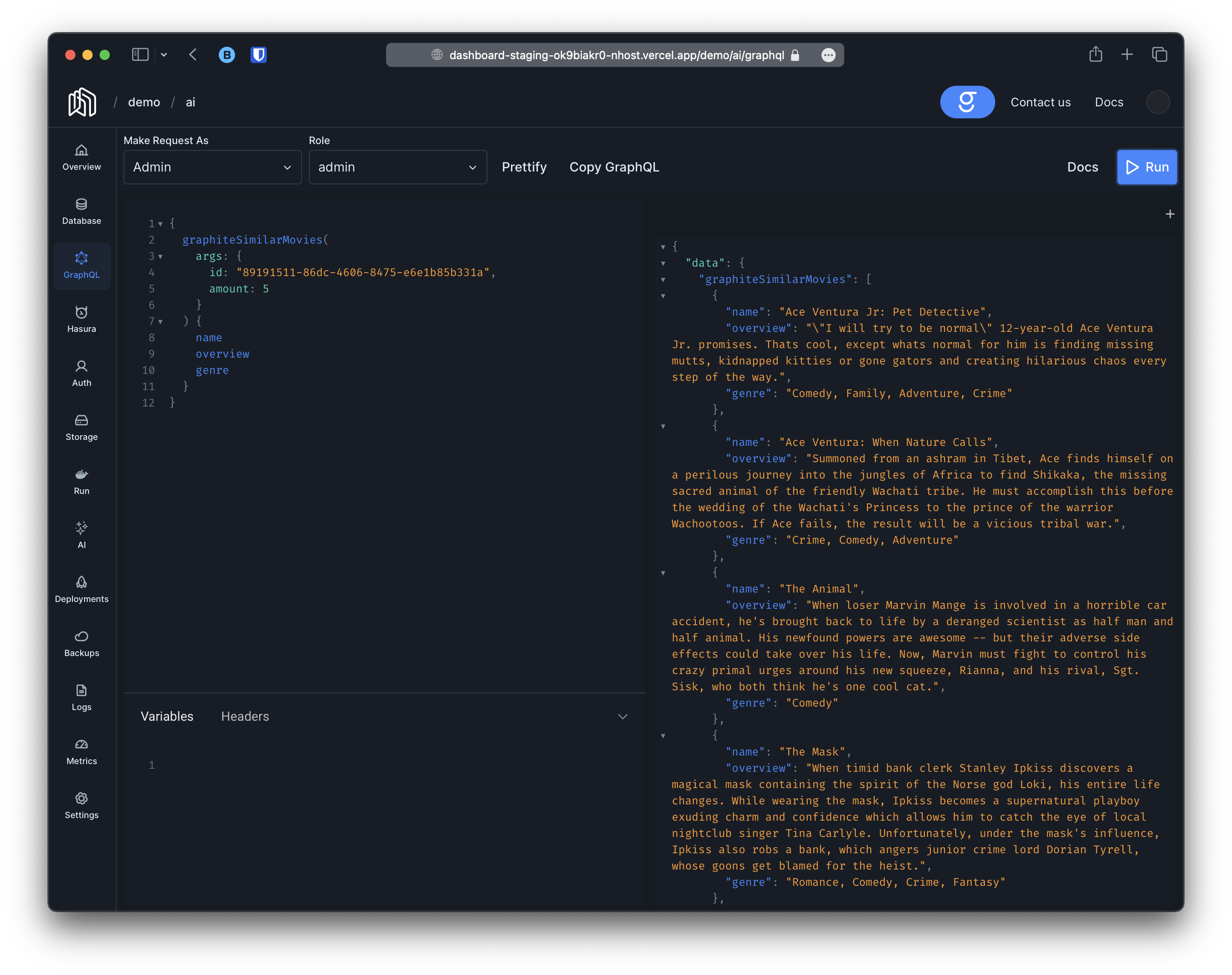
Both queries accept a third argument
maxDistance. This argument allows you to filter responses that are too far from the query, useful for ensuring that very specific queries do not return entirely unrelated responses. The argument is a float between 0.0 (an exact match) and 1.0 (completely unrelated), with a default setting of 1.0, ensuring the best matches are always returned even if they are unrelated to the query.